





Your Sexually Explicit Blogger/Blogspot Blog: An ErosBlog Recommendation
Subtitle: How To Tweak Your Robots.txt File So That The Wayback Machine Will Show The World What Google Refuses to Display
One of the reasons the adult internet will take such a hard body blow when Google makes sexually explicit Blogger (Blogspot) blogs forcibly private on March 23 is that in a single moment they will break millions of links around the web. As Violet Blue puts it:
When Google forces its “unacceptable” Blogger blogs to go dark, it will break more of the Internet than you think. Countless links that have been accessible on Blogger since its inception in 1999 will be broken across the Internet.
What’s your reflex response when you follow a link and find it broken? If it’s like me, you immediately click the link on your bookmarks toolbar that takes you to the WayBack Machine at the Internet Archive: https://archive.org/web/
The Wayback Machine and the Internet Archive’s crawling robot are powerful tools. Like all powerful tools, exactly how they work is sometimes obscure. Here are the basics: The IA crawler bot crawls the web, visiting as many pages as it can manage. And it stuffs those pages into the huge databases of the Wayback Machine, where the pages are preserved for all time, or anyway for as long as the Internet Archive can manage).
Preservation, however, is not the same as sharing and display. Some of the pages the Wayback Machine has in its databases are not displayed to the public. The reasons for this are covered in a complex FAQ, but for our purposes it’s enough to understand that sometimes when the IA crawler bot encounters a robots.txt file on a domain, that robots.txt file in effect tells the bot to go pound sand while pissing up a rope. And when the bot finds such a robots exclusion request, the bot politely backs away from the crazy person and (supposedly) refrains from capturing the current version of the pages. (See also: ROBOTS.TXT IS A SUICIDE NOTE)
In such a case (for reasons) the Wayback Machine will stop displaying any of the pages “protected” by the robot exclusion request. Any user requests will get this ugly red error instead:
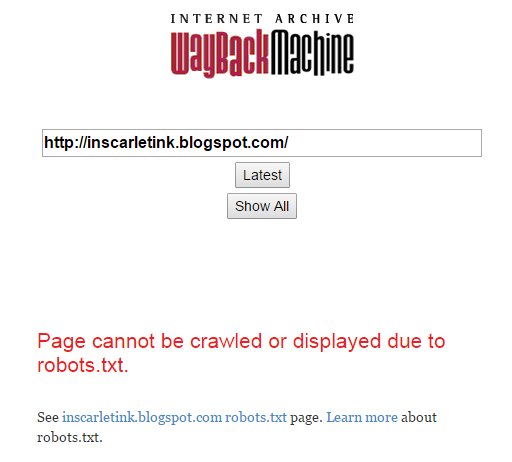
That’s so even if the IA bot has been to these pages a hundred times and has years of history in successive snapshots of the pages. If the robots.txt exclusion is present, the Wayback Machine refuses to display any of that old crawl data.
But note carefully what that explanation (and the Archive.org FAQ) does not say. The Wayback Machine does not display those old pages it still has in its database — but it certainly does not delete them from its database, either.
The Internet Archive and The WayBack Machine are not in the business of deleting shit. I take it as an article of faith that they for damned-skippy-sure never delete anything just because of a few lines in a robots.txt file.
Nothing on a website is there forever. That includes obnoxious robots.txt files. And when the robots.txt files go away, suddenly those old crawled pages become visible again. I actually saw this happen after Tumblr reversed itself in 2013 and at least temporarily stopped forcing a hostile robots.txt file onto its adult bloggers. The hostile robots.txt files stopped being so hostile, so the Wayback Machine could once again display the old pages that it had crawled and displayed upon request prior to Tumblr imposing the robots.txt files.
Consider now an adult Blogger (blogspot.com) blog that’s already private, because the owner chose to make it that way. Here’s the robots.txt file that Blogger displays by default:
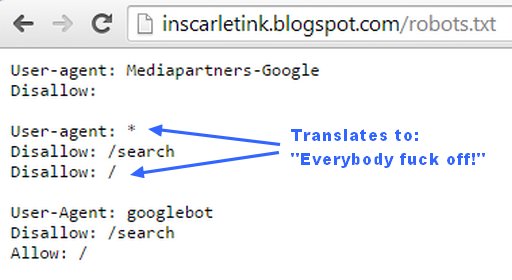
There’s a good chance (if only because Google hasn’t telegraphed any planned changes to the functionality of its private Blogger blogs) that this same exclusionary robots.txt will appear for every sexually explicit Blogger blog that is forcibly flagged “private” on March 23.
So, if you have a sexually explicit Blogger blog right now, there’s a good chance it’s in the Wayback Machine already, in whole or in part. (You can check: go here and paste your URL in the box.)
Now let’s fast forward to March 24th. Suppose I notice some old ErosBlog post that links to your Blogger sex blog. I click the link and it’s now broken, because Google has forcibly set your blog to “private”. If I ask the Wayback Machine to show me the old page for the broken link, I’ll get the ugly red error. But the Internet Archive still has that old page in its database. And someday, when things change, the Wayback Machine could theoretically serve the old page once again. (Google might change its policy. The Internet Archive might change its policy. Google might have gone bankrupt, or sold the Blogspot.com domain to America Online. The Internet might have changed beyond all recognition. The horse might even learn to sing, we can’t know.)
From a practical standpoint, this fact that the old pages of your blog are still in the databases of the Internet Archives — but barred from public display — doesn’t help us much. But if you feel that your sexually explicit blog is a legitimate part of the cultural history of the early 21st century, it matters rather a lot. Because your blog is not lost to history — it’s just lost to those of us who are interested in it right now.
(Yes, I am assuming that the Internet Archives will be successful in preserving and transmitting its data — our data — into the deep future. That’s by no means assured. If you have oodles of spare money kicking around, giving them some of your oodles would no doubt help assure it.)
Thus this post is, in part, a “don’t panic” message about all the sex blogs that are about to disappear from the internet. I called it a “hard body blow” at the top of this post, and it is. But it’s not a fatal blow. Yes, it will break a ton of our links and create a big dark hole in our adult internet. But it won’t, if the gods keep smiling on Brewster Kahle and his people, disappear those old blogs forever.
But I wouldn’t be well over a dozen paragraphs into this huge wall of text if all I had to say was “don’t panic.” Here’s an interesting thing that I just discovered about a blog on Blogger: Google currently allows blog owners to set the contents of their own custom robots.txt files, even on blogs flagged as private.
You can log into your adult Blogger blog right now and set a custom robots.txt file. If you want the Internet Archive to keep displaying archived pages once Google breaks all your inbound links, set it like this under Settings – Search Preferences – Crawlers and Indexing:
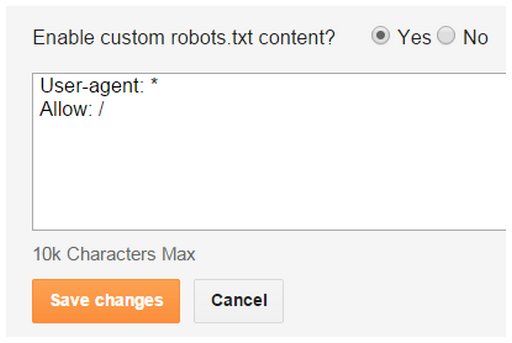
It can’t hurt anything, and it might mean that all your broken links can be “repaired” by people who encounter them. They will just paste the broken link into the Wayback Machine and be served a copy of the page as it used to be before Google went insane.
Will it work? Well, we don’t know for sure. Google could easily impose a uniform and restrictive robots.txt file on its adult bloggers after it forces them into “private” mode, by ignoring the custom setting or by removing it from the Blogger interface altogether. But — by design or oversight — Google might not do that, either.
If this trick does work, it means there will more traces remaining available to the public of your years of explicit sex blogging. And people who are bitterly disappointed by broken links to your stuff will have at least one useful thing to try.
Hopefully you’ll be taking more direct action too, like migrating your blog to private hosting. But if you can’t spare the resources to do that, this custom robots.txt change is a little thing you can do that may help a little.
P.S. If you have some technical skill and want to take a more proactive approach to saving our erotic cultural history, Archiveteam (these are the folks who saved Geocities, who also want you to understand they are not the Internet Archive) seems to have taken the news about Google’s erotic blog freakout as a sign that Blogger in general is no longer to be trusted. Because they have now announced they are “downloading everything”. This is great news, but it’s a project of epic size, and they can always use more help.
Similar Sex Blogging:
Shorter URL for sharing: https://www.erosblog.com/?p=13487

It’s bad enough we have to worry about fighting ISIS. I have enough to do just trying to pay the rent and put gas in the tank. Now we have to fight the bullies at Google too?
One of these days people are going to start going “postal” ala Michael Douglas in “Falling Down” (1993).
[…] Jason Scott of the Internet Archive has said that the group will attempt to preserve as much of the Blogger cannon as possible, but he strongly encouraged blog owners to do their part by independently saving their blogs themselves to the Wayback Machine. There are three ways to do this, and they’re all pretty much manual. You can do it through a web interface, with a JavaScript plugin, or a Chrome extension. And you may have to sneak in those robots. […]
It might also be worthwhile creating a local mirror of your site and others using httrack, a subject covered earlier at ErosBlog. It isn’t ideal, but it will preserve your content in at least some form that can be used for reconstructing the blog later if other efforts at preservation fail. And if it’s someone else blog, it will at least preserve content for your locally. I am contemplating doing this with blogspot blogs on the Erotic Mad Science blogroll.